CLI Quickstart
Overview
Use the Gradient Command Line Interface (CLI) to fine-tune a custom LLM with just a few simple commands.
📂 Create an account and workspace
If you haven't already, go to gradient.ai, click sign up and then create your account. Once you have verified your email, log in to the account. Click "Create New Workspace" and give it a name.
You can see your workspaces at any time by going to https://auth.gradient.ai/select-workspace.
🏕️ Set up your environment
Install the Gradient CLI
Choose the installation method for the operating system and processor architecture on which you use the CLI and follow the installation sets in the package.
Once the CLI is installed, you can check that it is working with gradient --version:
$ gradient --version
@gradient/cli_app/1.1.0 darwin-x64 node-v18.7.0
You will be able to update to the latest version of Gradient directly from the CLI.
If you have an error with Node.js installation (which should be bundled within our package), install it separately from here.
Authentication
- Before you can use the CLI, you need to authenticate with the service:
$ gradient auth login
✔ Your user code: 1234-ABCD
⠧ Go to https://auth.gradient.ai/user-code in your browser and enter the code
- While keeping the CLI open, open a web browser and go to https://auth.gradient.ai/user-code. Enter the code you were given.
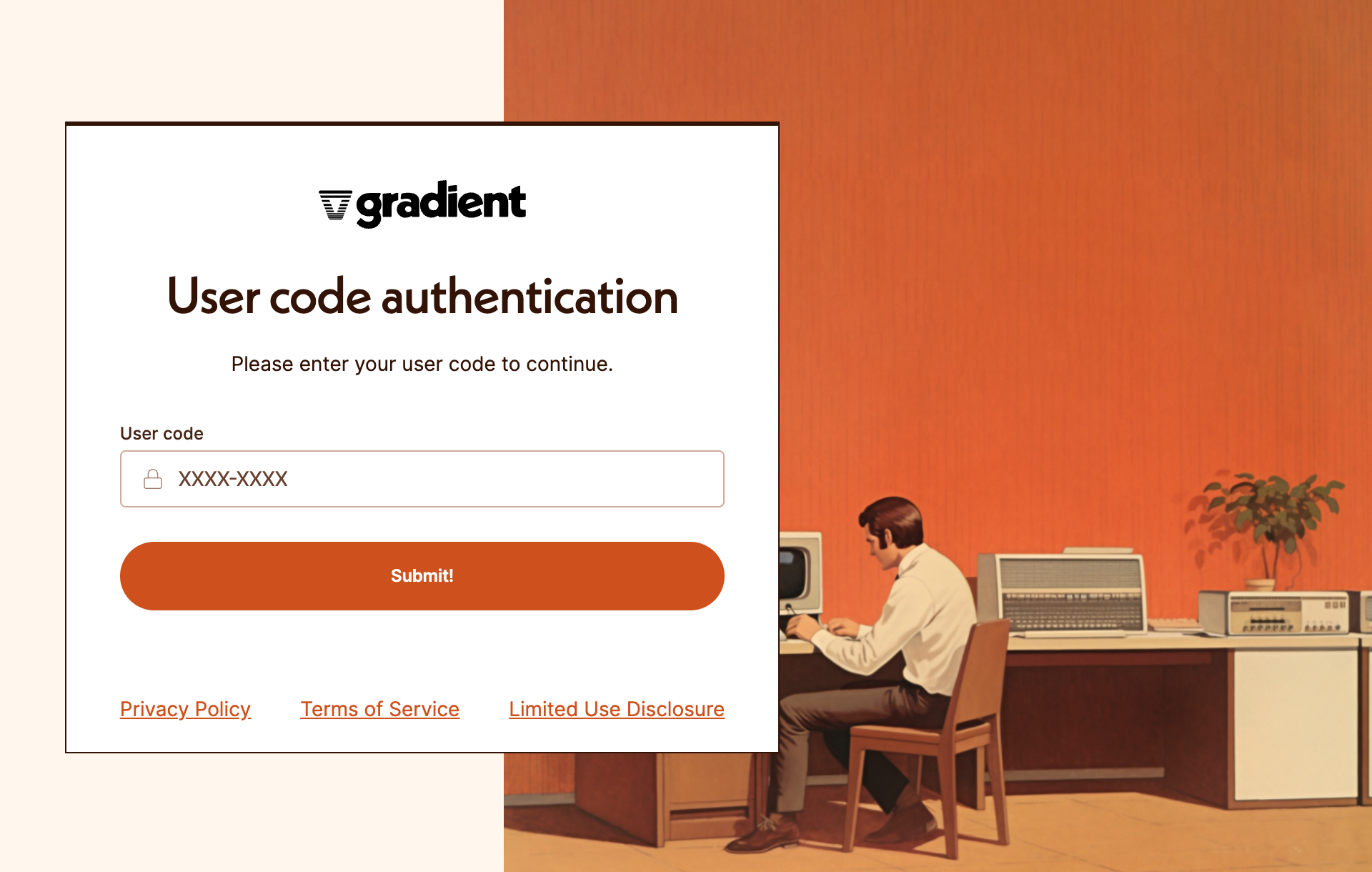
- Log in with your user information.
- Once logged in you are authenticated in the CLI.

- You can verify your authentication with
gradient auth status:
$ gradient auth status
✔ You are authenticated as Gradient User <[email protected]>
Select the default workspace
Now that you’re logged in let’s see the the workspaces you belong to. You can also manage and create new workspaces at https://auth.gradient.ai/select-workspace.
$ gradient workspace list
ID Name Users
────────────────────────────────────────────── ───────── ─────
0aac8f46-face-46b2-9ba9-955d36516566_workspace Gradient 6
f9d19c11-b818-4ad9-ab9e-7e82313b9399_workspace Gradient2 1
d2b95d14-6d87-447a-9245-d0bd4817a8f8_workspace Gradient3 2
Most of the requests that you submit to Gradient require a workspace. You can set your default workspace with gradient workspace set and selecting your workspace name from the list.
$ gradient workspace set
? Pick the default workspace: (Use arrow keys)
❯ Gradient
❯ Gradient2
❯ Gradient3
Gradient
You can check your default workspace with gradient workspace show:
$ gradient workspace show
✔ Default workspace ID set to 0aac8f46-face-46b2-9ba9-955d36516566_workspace
💾 Create a model instance
You can view the available models in your workspace:
$ gradient model list
ID Base Model Name Name
────────────────────────────────────────────────── ─────────────── ────────────────────────────────────
99148c6d-c2a0-4fbe-a4a7-e7c05bdb8a09_base_ml_model bloom-560m
f0b97d96-51a8-4040-8b22-7940ee1fa24e_base_ml_model llama2-7b-chat
cc2dafce-9e6e-4a23-a918-cad6ba89e42e_base_ml_model nous-hermes2
You can create a new model based on a base model with gradient model create <base-model-id> <model-name>:
$ gradient model create 99148c6d-c2a0-4fbe-a4a7-e7c05bdb8a09_base_ml_model testmodel
✔ Created a new model testmodel based on 99148c6d-c2a0-4fbe-a4a7-e7c05bdb8a09_base_ml_model!
📦 Prepare your dataset
The CLI performs fine-tuning by sending data samples from an external JSONL file. JSONL files are text files where each line contains a JSON object, also known as newline-delimited JSON.
Each data point should be formatted in a single line, in a templated format suitable for the base model you are fine-tuning on. We recommend using the Meta template for Llama 2, and the Alpaca template for Nous Hermes 2, as shown below. Note that the Llama 2 template offers a “system prompt” specification to help align the LLM responses. This is an advanced feature, and it is optional, so you may omit it.
In both template formats, you may see some unfamiliar markers. One is \n which is the marker for a new line, much like when you hit the enter/return key. These \n markers are part of the prompt structure, so be sure to include them in your own datasets, as we show below.
You will also see the <s> token and its complement </s>, which mark the beginning and end of sequences in the dataset, respectively. Different members of the LLM community seem to have different recommendations around including these tokens, but anecdotally some members of the Gradient team have found including them to be helpful, especially in multi-turn conversations with the LLM, so we are including them in our examples below. As you get comfortable with the fine-tuning process, feel free to try omitting them and see if it affects your results!
Llama 2 7b template
{ "inputs": "<s>[INST] <<<<SYS>>>>\n{{ system_prompt }}\n<</SYS>>\n\n{{ user_message }} [/INST] {{ response }} </s>" }
Nous Hermes 2 template
{ "inputs": "<s>### Instruction:\n{{ user_message }}\n\n### Response:\n{{ response }}</s>" }
Example data point:
Llama 2 7b example with content
{ "inputs": "<s>[INST] <<<<SYS>>>>\nYou are a helpful assistant who gives concise answers to questions about technology companies.\n<</SYS>>\n\nWhat is the address of the company known as Gradient? [/INST] 123 Main Street, San Francisco, CA 94107 </s>" }
Nous Hermes 2 example with content
{ "inputs": "<s>### Instruction:\nWhat is the address of the company known as Gradient?\n\n### Response:\n123 Main Street, San Francisco, CA 94107 </s>" }
Notes
For both templates, it is important to have the correct number and placement of \n and other spaces and/or punctuation to result in the best model performance.
Since the whole JSONL file is processed by the Gradient CLI there are no limits on the file size imposed by the CLI.
These are essentially starting points for formatting your prompts. Prompt engineering best practices continue to evolve based on new breakthroughs and for specific use cases. You can find some more templating information at Tips & Tricks. We encourage you to research the topic yourself and experiment to see what kind of results you can get!
🪄 Fine-tune your model
Call the command gradient model fine-tune <model-id> <json-filepath> to fine-tune your model:
$ gradient model fine-tune 9bc9e73a-f55a-45cc-9c62-a2674c7ec4c8_model_adapter ~/sample.jsonl
████████████████████████████████████████ 100% | ETA: 0s | 319/319
🦄 Fine-tuning completed!
🎁 Generating completions from your model
Test out your newly fine-tuned model using the command gradient model complete <model-id> <query-string>. Similar to the dataset preparation described above, your query string should also be formatted to match the appropriate base model you fine-tuned upon.
Llama 2 7b (query string only)
"<s>[INST] <<<<SYS>>>>\n{{ system_prompt }}\n<</SYS>>\n\n{{ user_message }} [/INST] "
Nous Hermes 2 (query string only)
"<s>### Instruction:\n{{ user_message }}\n\n### Response:\n"
Note that your completion prompt should end just before the place that was reserved for the response in the dataset that you fed in during fine-tuning. This sets the model up to fill in the blank according to that same pattern, resulting in a response that starts from where your completion prompt left off.
Also note the trailing space at the end of the Llama 2 prompt, just before the final close quotes. We have intentionally included that space, as we find that without it, the AI tends to start its response with an unwanted space. As with much in prompt engineering, however, feel free to experiment once you have tried the basics.
Example completion command:
Llama 2 7b
$ gradient model complete 9bc9e73a-f55a-45cc-9c62-a2674c7ec4c8_model_adapter "<s>[INST] <<<<SYS>>>>\nYou are a helpful assistant who gives concise answers to questions about technology companies.\n<</SYS>>\n\nWhat is Gradient's headquarters? [/INST] "
Nous Hermes 2
$ gradient model complete 9bc9e73a-f55a-45cc-9c62-a2674c7ec4c8_model_adapter "<s>### Instruction:\nWhat is Gradient's headquarters?\n\n### Response:\n"
To adjust the length of your completion, add --max-generated-token-count=<integer> to the end of the command. See our Tips & Tricks to learn about other techniques to generating completions.
🗑️ Deleting your model
If you decide you no longer want to train or generate completions with one of the models you created, you can delete it with the command gradient model delete <model-id> to prevent your workspace from getting cluttered.
Updated 5 months ago